Aug 2019 –
Aug 2020
Yorktown Heights, New York
One of the first 10 AI Residents at IBM, located at the Yorktown Lab. The AI Residency program provides an opportunity to conduct research and engineering in recent topics in Artificial Intelligence.
As a Resident, I have been involved in 2 lines of work:
Transfer Learning in Visual Reasoning:
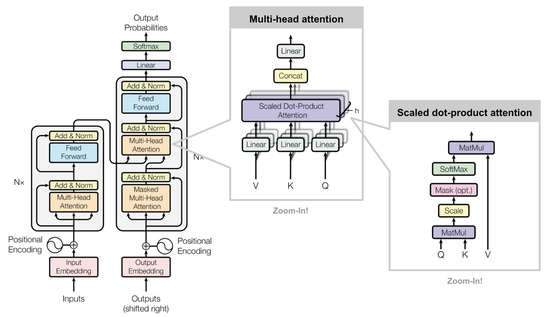
Transfer Learning is a sample-efficient method to boost performance on tasks where data is scarce, or difficult to access. However, it is unclear what a methodology for effective Transfer Learning could be. Building on my previous work on Visual Question Answering, and extending to Video Reasoning, we propose a new taxonomy on 3 axes: temporal transfer, features transfer and reasoning transfer.
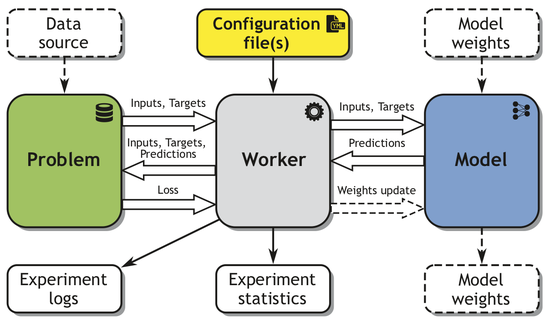
I took an active role in setting up the experiments and collecting the results, reusing the MI-Prometheus library I have co-developed.
Compositional Generalization:
People excel at imagining or recognizing complicated objects or scenes they have never seen before. We are able to recognize a new car by the composition of its parts: the windshield in front, doors on the sides, supported on four wheels. Even if the car is missing a part (say it’s an autonomous vehicle without steering wheel). we are still able to recognize it as a car. This is because our view of the world is fundamentally compositional.
It is natural to wonder whether neural networks, in the absence of any specific encouragement (bias) to generalize in this way, would do so. To address this, we analyzed whether neural networks are able to discriminate among different classes of visual objects.
I had several duties for this publication:
* I helped design the experiments and the hypotheses they test,
* I co-wrote the generation code to create the image samples we used in the experiments,
* I wrote the code for training the models, tracking the statistics and saving the results to file,
* Finally, I helped analyze the results and discuss them in the paper.