Summary
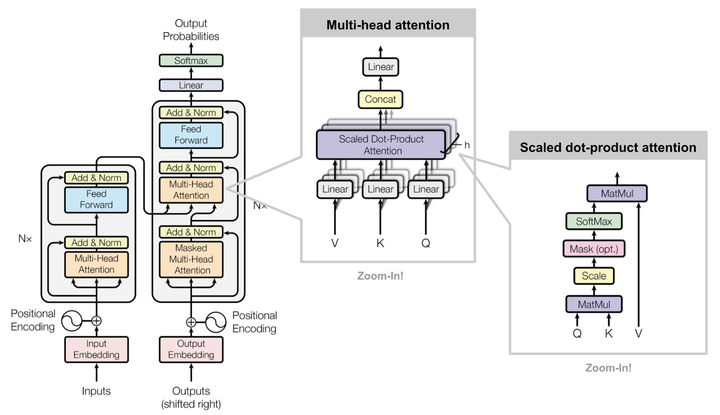
We propose an in-depth analysis and reimplementation of the Transformer model (Vaswani et al., NIPS 2017). Its non-recurrent behavior and sole use of attention makes it an intriguing model to analyze.
We perform a hyper-parameters search, as well as a memory-profiling study, both of these allowing us to successfully train and semantically evaluate the model on the IWSLT TED Translation task. Our experiments further enable us to detail particular insights on the behavior of the model and its training process. This article is aligned with the current question of reproducibility in Deep Learning Research.
Our findings are available on the main project’s webpage.